
Most past research in the area of serious games
for simulation has focused on games with constrained
multiple-choice based dialogue systems. Recent
advancements in natural language processing research
make free-input text classification-based dialogue
systems more feasible, but an effective framework for
collecting training data for such systems has not yet been
developed. This paper presents methods for collecting
and generating data for training a free-input
classification-based system. Various data crowdsourcing
prompt types are presented. A binary category system,
which increases the fidelity of the labeling to make free-
input classification more effective, is presented. Finally, a
data generation algorithm based on the binary data
labeling system is presented. Future work will use the
data crowdsourcing and generation methods presented
here to implement a free-input dialogue system in a
virtual reality (VR) simulation designed for cultural
competency training.
The overall goal of this research is to implement and test the effectiveness of a simulation for training US military officers to productively interact with their Chinese counterparts. On-screen multiple-choice options in an existing cross-cultural competence training simulation will be replaced with free response input collected using a speech- to-text system and a text classifier.
Investigating an effective method of cross-cultural competence training for Chinese-American interactions is a valuable research aim for two key reasons:
First, there are major cultural differences between the US and China.
Second, US intercultural interaction with Chinese civilian and military populations continues to increase according to several metrics. For example, the Chinese immigrant population in the US has grown more than six-fold since 1980 . The US military has participated in the annual joint Disaster Management Exchange (DME) with the Chinese military since 2005. The goal of DME is to improve the ability of the US military to respond to natural disasters in the Pacific region by training cooperatively with the Chinese military.
A key challenge when creating a free-input training simulation is obtaining sufficient data to train classification models that will have the ability to replace the multiple- choice dialogue system. Methods for collecting, generating, and labeling data for creating a free-input dialogue system were investigated. These methods have the ability to produce a robust corpus for accurately classifying speech in a training simulation. While a great deal of effort is required to build such a corpus, this framework could be effective for a variety of free- response classification problems, especially in the realm of avatar-based behavioral training simulations.
Evaluation and Results
We got thousands of ways of saying something for every question. We used this data to train our models and we used f1-score as a metric for every question as wanted to minimize the number of false positives and false negatives. Here are the results -
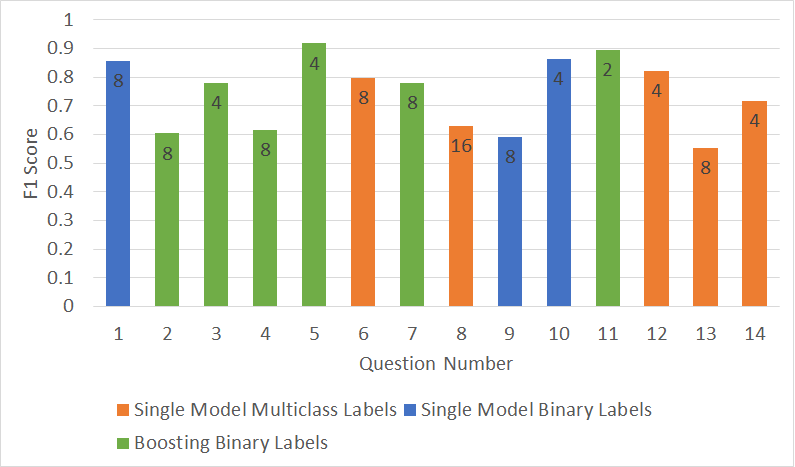
80% of the users declared that the system accurately judged what they were saying and provided apt feedback
and the system is currently being reviewed by ARL to determine if they can use it for their training purposes.
| Visit: | Project link |